Serialisation. This compelling event for the pharmaceutical industry is now being tackled by the OPC foundation Open-SCS working group. Though a bit late to the game for a number of markets, its still of value for all future implementations for new drugs.
One of their main objectives is to standardise the data exchange requirements for serialisation. The working group is only kicking off now but we are looking forward to being actively involved. Their working group focusses on an OPC-UA / ISA-95 / ISA-88 implementation which is of course exactly what Spike is.
One way to approach a serialisation challenge is to wireframe out all the Actors (systems) and their data exchange requirements. So at least you know what you want your systems to do and what info they require when, in an ideal scenario. Then its a case of working back from there to find out whats actually achievable in the time lines.
Spike provides a transaction module specifically for this purpose.
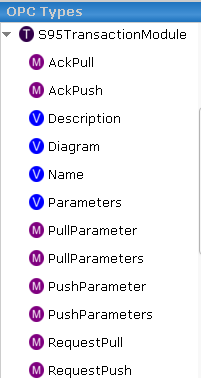
OPCUA itself is primarily just an object oriented communication technology and not a database technology (so it doesnt have transactional recording capability natively) . If you know what WebAPI is, then you have a good idea of the power of OPCUA. OPCUA can even pass files between OCPUA servers. This is just one of the main reasons behind why it is a core Industrie4.0 technology in Germany ; OPCUA is used to pass bill of material data between machines in realtime. The format of the files is generally XML such as AutomationML but could be PackML or BatchML. You just need a system that can serialise and deserialise at either end. (We provide python helper functions for this purpose in Spike2.0)
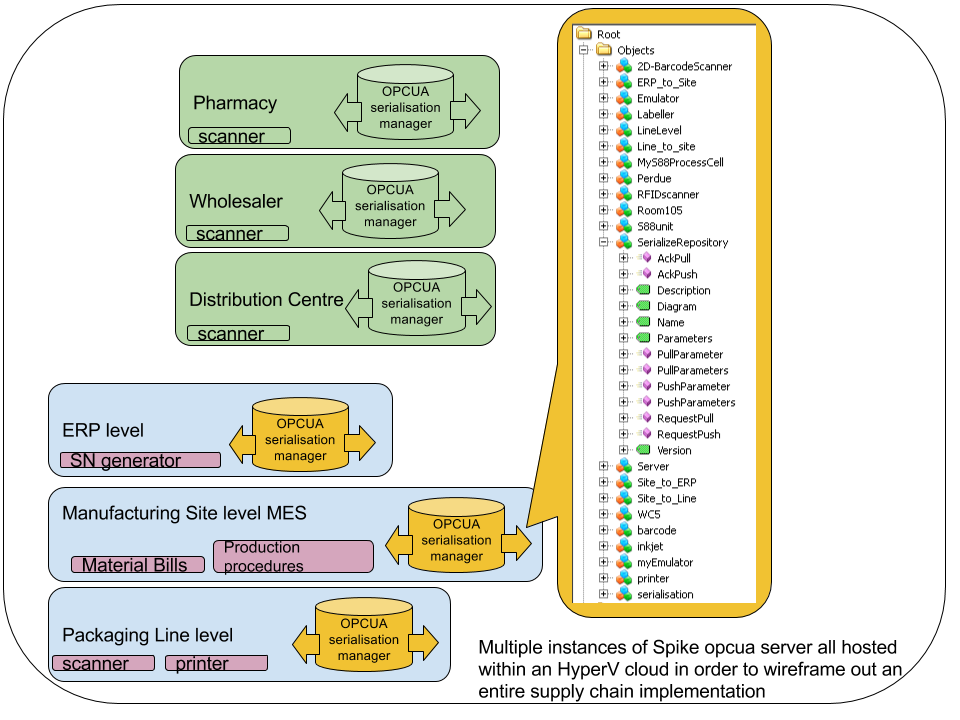
How do I wireframe my entire supply chain in order to get a handle on the scope and size of my serialisation challenge?
If you have a HyperV box, then you can run a virtual machine (VM) for every major system in your supply chain. To keep things simple, you can put them all on the same IP subnet and make them all part of the same security domain. On each VM you could run an OPCUA S88 / S95 modelling system (for example our own Spike!). Then you can go about defining the transactional information ebb and flow between the systems.
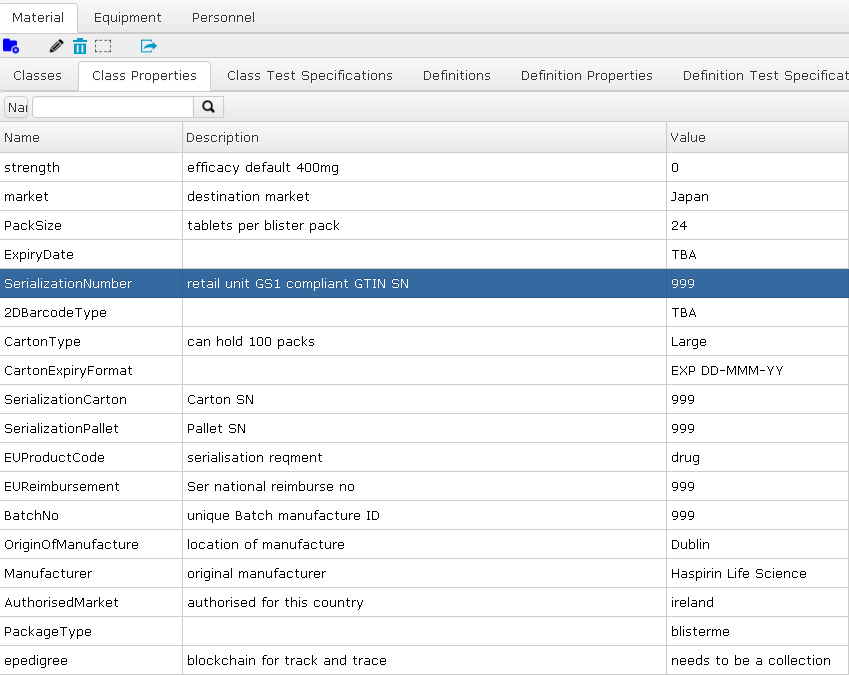
Heres a stab at some of the additional material class properties that may be required in order to implement serialisation on top of an existing MES system. (Disclaimer! The following was gleamed from a number of public domain articles, not a real project. So its unlikely to be accurate. The good news is, it only takes seconds to add and delete material class properties in Spike.)
As per S95, the material class is only a template for a material definition which is effectively an ‘instance’ of the material class. Finally, the actual serialisation data is associated with a material lot that is a specific batch of material defined as per a material definition. We are looking for industry partners to further flesh the implementation out. So if you are interested, then please get in touch or check out this video showing S95 implementation in Spike.
Comments are closed.